
Well, huh.
I didn’t expect OpenClaw capable of playing a game until it proved me wrong. There’s a lot of reasons why gaming and an OpenClaw instance don’t work: inference time, the harness used, the type of game. Yet, suddenly it did.
Where it started
It started with test footage. I grew tired of testing various site changes. Instead of having to logon to the website to view the changes, why couldn’t the discord bot just use it’s video tools to record video footage and send me proof the change worked? I reasoned that if the bot discovered an error in process of such a recording, then it’d fix the error before it sent me the video. This works unbelievably well, by the way.
It worked so well I had a bigger thought: could the OpenClaw agent playtest games?
That seemed unlikely. I’ve done a ton of game experiments with LLMs. There’s lots of games where LLMs can ostensibly play, but there are factors like time to first token, inference time, and more.
What I expected
I expected was what I’ve seen several dozen times in other types of games: the agent would move a character, get stuck, and need help. Only that’s not at all what happened. The agent completed the level. No instruction. No training. It just… solved level one.
The Mazefall
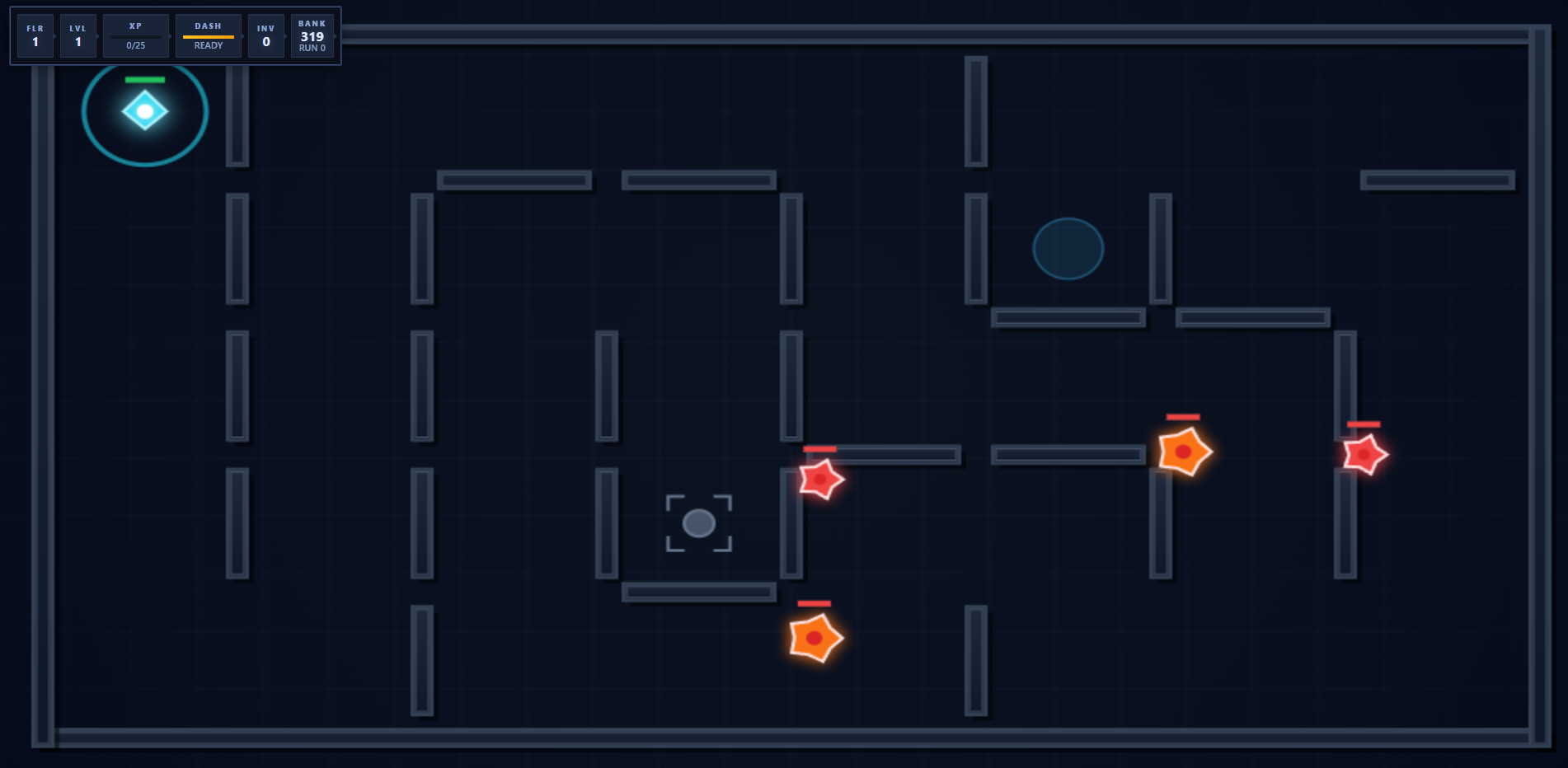
Mazefall is a little web game I started as an experiment. I’ve written on it here. It’s a game that has no pre-existing priors really. It’s a fusion of a handful of games.
Agentic AI Skills - Pixel Art Skill.md
Eric Rhea·Mar 23Read full storyI find it rather interesting, and something I assumed was just out of reach of what an LLM could solve-it would need to play the game in realtime, after all.
This video is recorded in realtime of a LLM solving a maze. How did it do it? Well, the answer surprised me. It might surprise you, too. It’s a short video. Watch and see.
The Insight
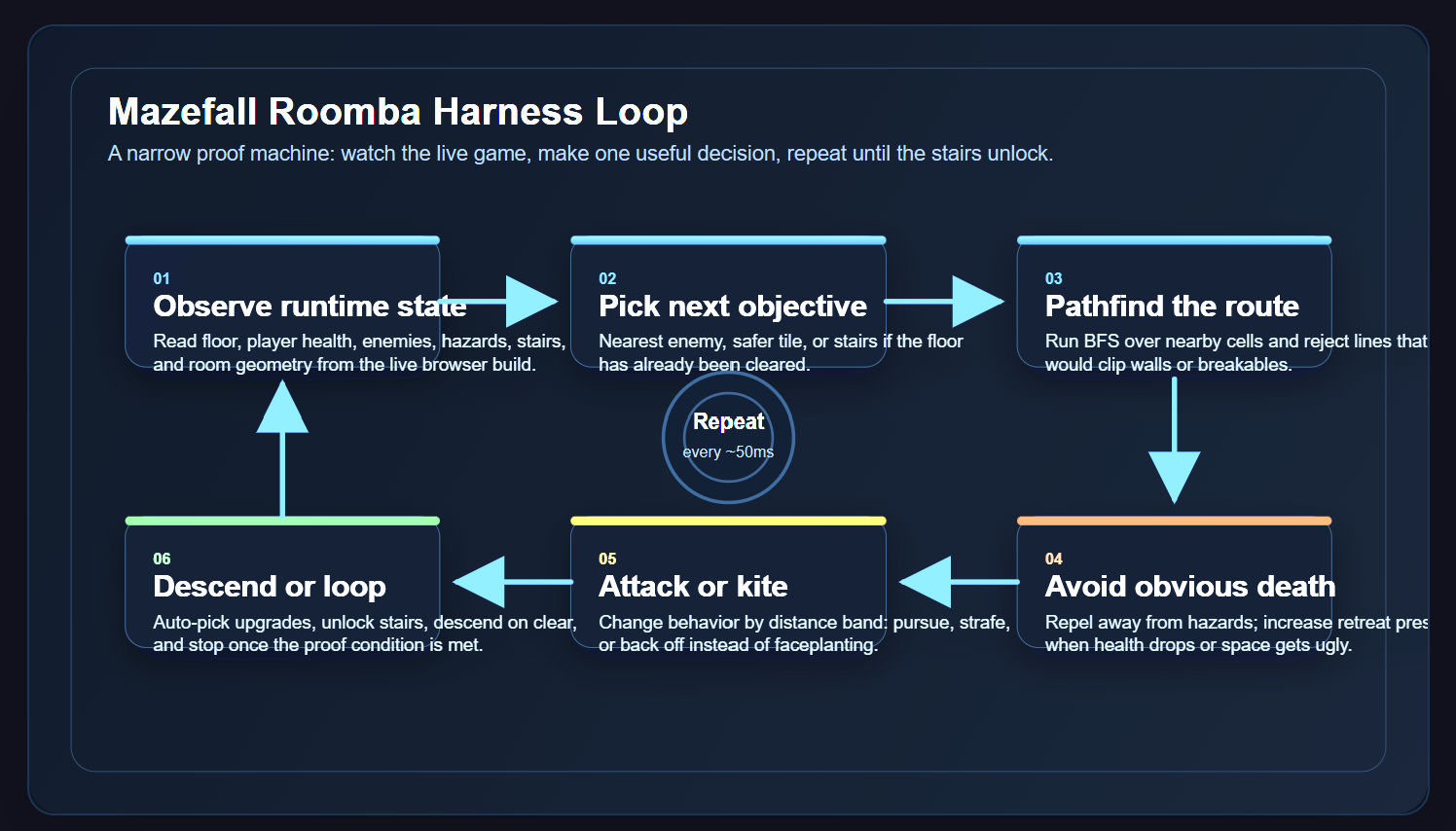
What I learned from this is that OpenClaw can play games. In fact, it can play any game with a few caveats. It’s writing it’s movesets and game moves as tiny scripts before the action. This is a key step. It’s writing code just-in-time. Not full apps, just little throw-away apps that solve the problem and then get feedback and try again. This was a huge lightbulb moment for how I’ve been thinking about games with LLMs all wrong: I thought I’d create a harness for the LLM to steer. This is wrong. The LLM needs a harness it can submit execution plans and then see the results.
The entire time I’ve been trying to just send raw input controls to the LLM and have it make sense of those, but that’s flawed and wrong. The LLM doesn’t need realtime feedback as a context stream.
It just needs to know if it’s time to submit a new program.
But it also can just build the solution as an optimization step.
The breakthrough is not that agents can use software. It is that, when the goal is measurable, agents can often invent the harness they need instead of waiting for a human to build one.
The Agent Built the Harness. I Just Gave It a Goal.
I used to think the hard part of getting an AI agent to use software was building the harness.
If I wanted an agent to play a game, test a website, or navigate an application, I assumed I had to design the control layer first. Expose the right inputs. Track the right state. Build the loop. Then, and only then, let the model operate inside it.
One of my OpenClaw agents just broke that assumption.
I pointed it at a web game I built called Mazefall and gave it a simple objective: get to the next floor. Not “play well.” Not “show me what you can do.” Just clear level one and reach level two.
I expected the usual result. It would move around, get stuck, and eventually need help.
Instead, it solved the level.
Not just the maze. The full objective. It navigated the floor, defeated the enemies it needed to defeat, unlocked descent, and completed the level. Then it sent me video proof.
That was not the surprising part.
The surprising part was realizing that my mental model was obsolete.
What I thought was required
I had been operating with an old assumption: if you want an AI agent to do something nontrivial in software, you need to build a custom harness for it first.
That assumption comes from real experience. Most automation systems have worked that way. You create the interface. You decide what matters. You reduce the messiness of the environment into something the system can reliably act on.
That still matters in some cases. But it is no longer the whole game.
What happened with Mazefall was different. The agent checked the controls, read the game code, inferred how the floor objective worked, and built the harness it needed on the fly. Its first attempt got stuck. It changed approach. Then it cleared floor one and descended to floor two.
That is a different category of capability.
The story is not “an LLM played a game.” The story is that the agent generated the control system required to solve the game once it had a clear target.
Why the goal mattered

The key prompt was not sophisticated. It was something close to this:
record yourself playing to the next floor. kill enough NPCs that you can descend to the next floor.
That worked because the goal was measurable.
“Play the game well” is useless. It is subjective. It gives the agent no clear finish line. “Reach floor two” is different. The game can tell you whether that happened or not. The environment contains the success condition.
That distinction matters more than most people realize.
I used to think I needed to build complex harnesses for AI to play games or use software. Now I think the more important job is to make the target measurable and easy for the model to understand.
Once that exists, the agent can often build more of the bridge than I expected.
The real superpower
The real power is not pointing an LLM at a problem and hoping for a clever answer.
The real power is pointing an LLM at a problem, giving it an execution environment where it can run many tiny programs, and letting it learn from the results.
That is the shift.
The agent did not need a giant bespoke framework. It needed a goal, access to the environment, and permission to generate small disposable tools that moved it toward success. It could inspect the code, test an approach, fail, revise, and try again.
That loop is the superpower.
Not raw reasoning in isolation. Not realtime control streams shoved directly into a model. Execution, feedback, revision.
Small programs. Fast loops. Clear outcomes.
That is a much stronger pattern than “give the model controls and let it steer.”
This goes far beyond games
Games just make the lesson obvious.
The same pattern applies anywhere the outcome is measurable and the environment can return clear feedback.
In website QA, the goal might be “complete signup and land on the dashboard without errors.” In data work, it might be “produce a clean table with zero schema violations.” In software testing, it might be “trigger the bug, patch it, and pass the regression suite.” In finance operations, it might be “reconcile these transactions to within one cent and flag the exceptions.”
The pattern is the same every time.
Clear goal. Executable environment. Cheap repeated attempts. Hard feedback.
That is also why systems like Karpathy’s autoresearch are so interesting. The agent is not told to “do good research.” It is given a bounded loop. Make a change. Run an experiment. Check the metric. Keep or discard. Repeat. The intelligence is not floating free. It is grounded in a system that can score the work.
Once you see that, a lot of agent design starts to look different.
What still belongs to the human
This does not remove the human from the process. It changes the human’s job. It’ll likely be what teams shift towards-defining outcomes. Once you can clearly articulate the what, the how is automatic.
See, the human still has to define the objective-it’s hard to imagine a world where that changes because compute is scarce. The human still has to decide what counts as success. The human still has to set the boundaries, the allowed actions, and the acceptable risks.
What the human may not need to do, at least as often, is pre-build every harness by hand.
That is the part I am rethinking.
For a long time, I assumed the bottleneck was control. Now I think the bottleneck is often goal design. If the target is vague, the agent will drift. If the target is measurable, the agent can often discover more of the path than I expected.
Mazefall made that painfully clear.
I thought I needed to build the harness.
Instead, I learned I need to get out of the way.
Read more from Kira on the harness built to solve Mazefall at https://www.ericrhea.com/gamelab/mazefall-roomba-harness.html
Thanks for reading! Subscribe for free to receive new posts and support my work.
SubscribeSource: https://advisoryhour.substack.com/p/when-openclaw-beat-level-one
← Back to OpenClaw