The question under the experiment
The original field note asked a deliberately narrow question: how much useful behavior can fit inside a model small enough to feel almost unserious? A 64 MB model running RPG combat logic is not a general assistant. That is the point. It is a test of whether a tiny learned system can absorb a constrained grammar, emit plausible state transitions, and expose where the representation breaks.
That question now has a larger context. The SLM survey frames small language models as a serious research lane for accessible, affordable, efficient intelligence, while Phi-3 shows that compact models can matter in practical deployment contexts instead of serving only as toy baselines.
From prompt to game engine behavior
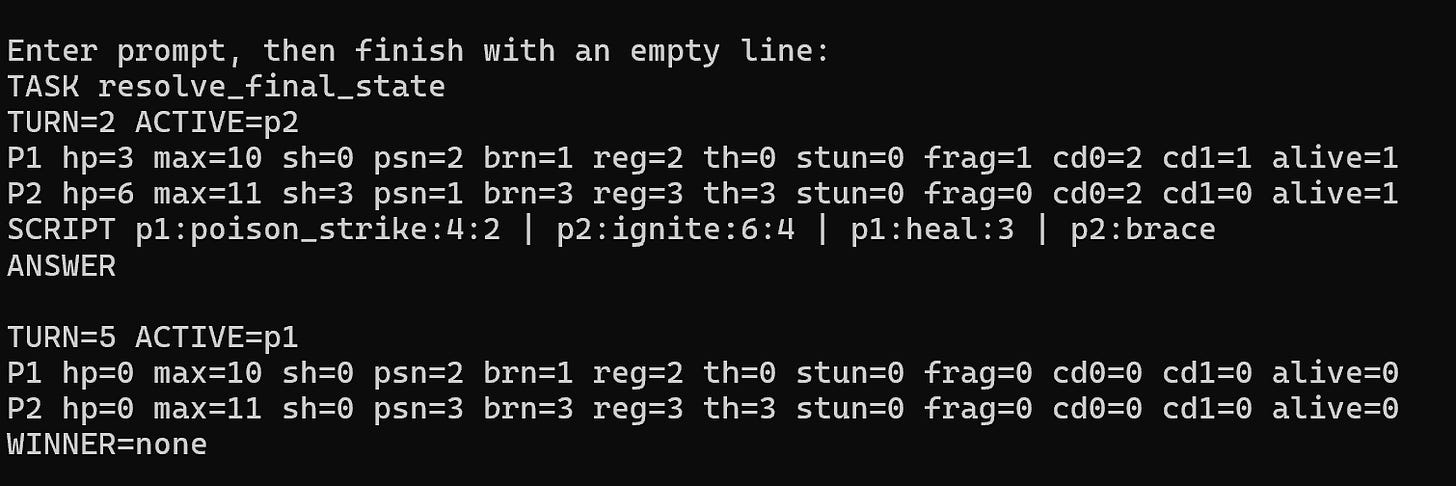
The model is trained on a compact, template-driven format representing turn-based RPG state. Inputs encode turn counters, status effects, cooldown slots, and actions like poison_strike, ignite, heal, and guard. Outputs resolve toward a canonical next-state block.

That makes the model behave like a fuzzy state-transition engine. Not deterministic code, but learned transitions with enough structure to produce coherent combat outcomes under normal conditions.
- Status channels: shield, poison, burn, regen, thorns, stun, fragile, cooldowns.
- Action grammar: attack, heal, guard, cleanse, poison strike, ignite, brace, wait.
- Goal: infer and emit consistent post-turn world state.
Where nanochat changes the frame
nanochat is useful here because it treats small-model training as an end-to-end system instead of a mystery box. The repo covers tokenization, pretraining, finetuning, evaluation, inference, and a chat UI, which is exactly the pipeline view a tiny specialist needs.
The important contrast is scale discipline. My RPG experiment starts at the very small, domain-specific end. nanochat shows the same discipline at a more general LLM scale: change the model depth, keep the pipeline coherent, evaluate with comparable metrics, and learn where the curve bends.
The useful failures
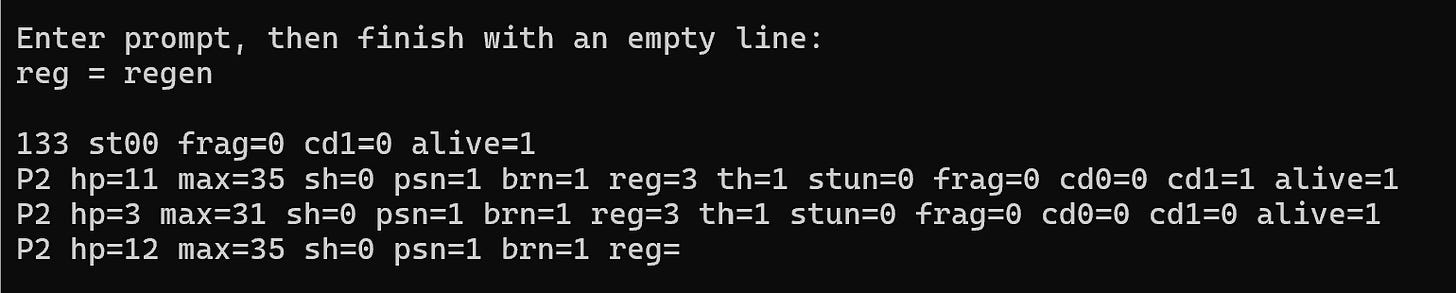
The best part of the note is not that the model works. It is where behavior degrades: label collapse, token drift, and boundary confusion when malformed or overloaded labels are introduced.

These failures map the model's internal compression limits and expose where representation quality breaks down. In practical training terms, they tell you what to fix next in data format, token conventions, and eval coverage.

What this means for custom model training
- Define a constrained domain: tiny models win when the task envelope is explicit.
- Treat formats as architecture: token names and templates are model design, not decoration.
- Build failure-first evals: perturb labels, action order, and edge states early.
- Measure capability-per-megabyte: this can be more useful than raw benchmark flexing.
- Design for composition: multiple tiny experts can beat one heavyweight generalist in real product loops.