Source note: Originally published on Eric's Advisory Hour Substack. Read the canonical post.

Local Inference
Can local inference be useful? Is there a way to NOT use ollama? I have a NPU snapdragon. What can I even do with it? The microsoft demos in the AI library suck. These thoughts and many more ran thru my mind.
A NPU can be useful. It will not replace Codex or Claude Code.
The Edge
When is speed necessary?
I’ve been thinking about speed. Everyone and their dog is slinging together advanced agentic flows, dozens if not hundreds of agents. And why? That part is less clear to me. I see a lot more software. More software isn’t useful software. It’s like going in the library. There are more books in a library than you can read in a lifetime. What book matters? Speed of output is related to this.
If you build agentically, then you have loops that don’t need subsecond timing. In fact, you might be OK with “if it takes two hours, I’m fine-after all I’m asleep” timing. Would you trade output time for lowering costs? I would.
Have you read the book, the Goal? If not, pause. Go read the book, then take time to make sense of what it’s saying. I’ll try to explain an idea in the book here.
If you agentify a hamburger stand, then you get instanteous hamburgers. You place the hamburger stand in a town of 1200 people. I grew up in a town this sized. How many hamburgers do you need? Did you really need instant hamburgers?
Of course not.
The purpose of the hamburger stand isn’t about the hamburger: yes, it’s part of why that hamburger stand is important. The other part? It’s a social hub. In a town of 1200, people are a tribe and community. The hamburger stand is the third place.
If you find yourself not fully understanding, then I encourage you to take time to run the thought experiment in your own community. If you could create an “instant” version of any material good, then play thru the first, second, third and fourth order impacts. Have a voice chat with ChatGPT.
I remain convinced I’m right about this, and by sharing this lesson you have a little edge on your competitors, too. Few are thinking about this.
Now let’s go back and tinker in the garage.
The Harness
I built the harness to solve several problems with my local models. I’ve walked this path before. This time I took a right instead of a left. Let me explain the specific slash commands and why I added them.
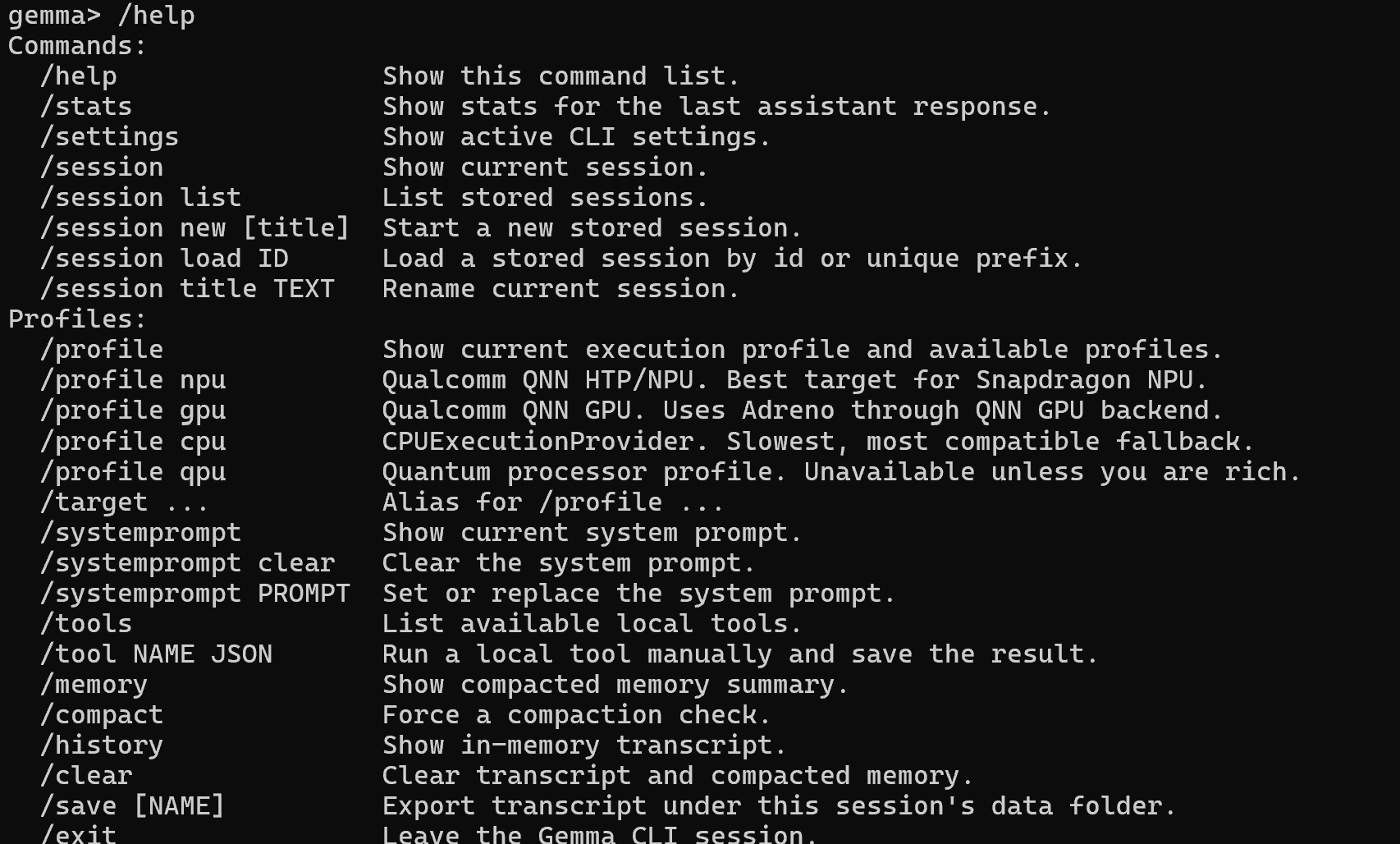
/systemprompt
The system prompt is what controls the model’s output. It’s the personality or character creator. I assume if you read my articles, then you have a fair idea what systemprompt is. What if you wanted to swap a system prompt on the fly in a session, reset it, or show what it is from the command line? I like easy things. It makes things clear.
/profile
There’s an alias for /target because I found myself reaching for /target as often as /profile. Why would I want these targets? I couldn’t quite tell when the ONNX models were loading into GPU versus NPU. If you read the chip architecture, then you’ll see the memory address space is largely shared between them. I need to do a deeper dive into the NPU chip. Custom inference chips are just interesting. They’re weird magic.
/tools
Imagine: you can chat with a local model but you want it to do useful things. Useful things require tools. What if you setup tool calls for your local ai so it can handle certain tasks? So it’s not just a chat, it’s an agent.
/memory
/compact
One of the big lessons in local models that I learned with ollama is that you start with compaction and memory solutions from the very beginning. Don’t add them later. Start there. Once you get the core loop up, immediately add context management tooling. Your future self will thank you. These /slash commands are in that line. Compaction is a solved technology paradigm, largely and everyone and their brother has written approaches on how to do this. I don’t have a “best” version of this that I’ve found I really like. I assume someone in the opensource community will one day stand up the “ultimate compaction repo” as it’s a problem everyone has.
Live Harness Demo
I recorded a video of my gemma harness. It walks thru setting a system prompt, and then the model gets to work. This won’t win speed records. And yet? The model not only answers my prompt-doing so in a way that’s aligned with the system prompt. Fully local. No external API calls. Running on battery.
This is running on my Microsoft Surface tablet. I unplugged the power cord.
Battery powered AI solving a real task, and then some.
Any strange benefits so far?
Theoretical ones. I’ll write about real ones after more experimentation.
Here’s an idea for you: Have Codex use the CLI to drive NPU and defer down some tasks to Gemma. Conceptually: stretch usage quota this way to longer runtime and tasks.
Also, I have three big virtual world projects. What if one of them had local inference powering more complex flows? After all, not all of us have unlimited token budgets
Did you dead my essay on why AI isn’t writing my posts now? I’m intentionally applying writing techniques.
Today’s writing technique: Orwell’s anti-bullshit pass. If the sentence is foggy, the thought probably is too. Lot of times this happens with the corporate jargon or when words ending with -ly rain into a blog post.
Thanks for reading! Subscribe for free to receive new posts and support my work.
Original source
This local copy preserves the article text, source link, and inline media. Canonical Substack URL: https://advisoryhour.substack.com/p/npu-and-gemma4-gemma-4-e2b-it-onnx.